مقدمه
روش های مدلسازی زیستگاه از دهه هفتاد میلادی با توسعه روش (HEP (Habitat evaluation procedure توسط سرویس حیات وحش و آبزیان ایالات متحده آمریکا (US Fish and Wildlife Services ) شروع و گسترش یافت و در مدیریت حیات وحش مورد استفاده قرار گرفته و ابزاری مناسب برای غلبه بر این مشکل معرفی شده اند. مدلهای پیش بینی کننده مطلوبیت زیستگاه بر اساس متغیر وابسته به دو دسته مدل های وابسته به داده های حضور و عدم حضور و مدل های وابسته به داده های فقط حضور تقسیم بندی می شوند. در معنای عام زیستگاه جایی است که یک موجود در آن می زید. تمامی جانوران تنها در جایی می توانند به زندگی ادامه دهند که نیاز های اولیه آنها شامل غذا، پناه و آب فراهم است و سازش آنها با محیط اجازه مقابله با شرایط سخت اقلیمی، رقبا و صیادان را می دهد (Morrison و همکاران، )موجودات به ویژگی های شکلی و ساختاری محل نیز توجه می کنند و در صورت تناسب این ویژگی ها از آن به عنوان زیستگاه استفاده می نمایند (David Lack ) در این راه، ،محققان دیگری نظیر سواردسون و هیلدن ( Soardson ، Hilden ) بیان نمودند که برای انتخاب زیستگاه، ،جانوران نخست ویژگی های کلی و عمومی محیط نظیر اقلیم را در نظر می گیرند و سپس در اقلیم مناسب بر اساس ویژگی های ریزتر به انتخاب زیستگاه خاص می پردازند. در این خصوص حتی ویژگی های بصری و آنچه که به چشم می آید نیزمهم است ( Harris ) افزون بر آن، نقش ژن ها و یادگیری در انتخاب زیستگاه نیز مورد بررسی قرار گرفته و بیشتر ،عقیده بر این است که ژن ها نقش مهمی در انتخاب زیستگاه دارند. لیوپولد معتقد است که تازه در اوایل قرن بیستم، هنگام استفاده از دانش زیست شناسی برای ،مدیریت حیات وحش دانشمندان متوجه شدند که چقدر در مطالعه روابط میان موجودات و زیستگاهشان کوتاهی شده است ومثلا برای رفع این مشکلات بوده است که پژوهشگری نظیر استودارد به مطالعه زیستگاه بلدرچین ،پرداخته است.
مدل
مدل ای از واقعیت است، که به صورت ریاضی یا توصیفی با استفاده از علائم و کلمات بیان می شود. فرآیند تبدیل هر سیستم فیزیکی یا زیست شناسی به مجموعه ای از روابط ریاضی و اجرای عملیاتی با سیستمهای ریاضی مزبور اصطلاحاً تجزیه تحلیل سیستمها خوانده می شود .سیستم ریاضی را در اصطلاح مدل می گویند. در واقع مدل چیزی نیست جز بیان تجریدی ناقصی از دنیای واقعی. در سالهای اخیر تعیین وضعیت پراکنش و توزیع گونه ها و وضعیت زیستگاههای تحت اشغال آنها از اهمیت به سزایی در برنامه های حفاظتی و مدیریت حیات وحش برخوردار شده است .اما مشکل زمان و بودجه قابل دسترس برای مطالعه گونهای از حیات وحش در مقیاس وسیع دشوار و در بسیاری از موارد غیر ممکن است . لذا روشهای مدلسازی زیستگاه که از دهه هفتاد میلادی با توسعه روش HEP توسط سرویس حیات وحش و آبزیان ایالات متحده آمریکا شروع و گسترش یافت در مدیریت حیات وحش مورد استفاده قرار گرفته و ابزاری مناسب برای غلبه بر این مشکل معرفی شده اند. در دهه 99 میلادی با توسعه سیستم اطلاعات جغرافیایی و تصاویر سنجش از دور، حرکت جدیدی در رشد سریع این مدلها ایجاد شده و در حال حاضر روشهای مدلسازی متنوع و نرم افزارهای متعددی برای این هدف توسعه یافته است.مدلهای توزیع گونه یک استراتژی بسیار متداول برای برآورد توزیع جغرافیایی واقعی یا پتانسیل گونه است. اساس کار این مدلها کمی کردن روابط بین توزیع گونه و محیط زیست پیرامون است . این مدلها به طور مشترک از ارتباطات میان حضور گونه و متغیرهای محیط زیستی، برای شناسایی محیط زیستی که توانایی نگهداری جمعیت را دارد استفاده میکنند. سپس توزیع فضایی محیطهایی که مناسب زیست گونه هستند فراتر از منطقه مورد مطالعه شناسایی میشود . مدلسازی پیشبینی توزیع گونه ها یک ابزار مهم دربوم شناسی وزیست شناسی حفاظت بوده که قابلیت کاربرد در برنامه ریزی حفاظت، تکامل، مدیریت گونه ها یا برطرف کردن تضاد بین انسان و حیات وحش و سایر موارد را داراست .مدلهای توزیع گونه اساسا نیازمند دو نوع داده ورودی شامل داده های محیط زیستی زمین سیمایی که گونه در آن یافت میشود و دادههای زیستی نقاط حضور گونه هستند . نقاط حضور گونه معمولا به صورت، نقاط جغرافیایی با طول و عرض مشخص در یک سیستم مختصات متداول ایجاد میشوند. متغیرهای محیط زیستی در بر گیرنده منطقه مورد مطالعه نیز که از قبل توسط کارشناس گونه یا مرور منابع انتخاب شده اند در محیط سیستم اطلاعات جغرافیاییبه مجموعه ای از لایه های رستری تبدیل میشوند.الگوریتم های بسیاری برای مدلسازی احتمال حضور و عدم حضور گونه به کار برده میشوند. وظیفه این الگوریتم ها شناسایی ارتباطات غیر خطی پیچیده در فضای محیطی چند بعدی است. نیاز به داده های عدم حضور یک تفاوت کلیدی میان این الگوریتم هاست. مدل های پیش بینی کننده مطلوبیت زیستگاه بر اساس متغیر وابسته به دو دسته مدل های وابسته به داده های حضور و عدم حضور و مدل های وابسته به داده های فقط حضور تقسیم بندی می شوند. یکی از مشکلات اساسی مدل هایی که نیاز به داده های حضور و عدم حضور به عنوان متغیر وابسته دارند، نبود داده های عدم حضور مطمئن است.یک گونه ممکن است به علل مختلفی همچون انقراض موقت محلی، عدم مشاهده در زمان نمونه برداری، وجود موانع پراکنش و نامطلوب بودن زیستگاه در بخشی از زیستگاه مشاهده نشود. تنها مورد آخر را می توان به عنوان داده عدم حضوردر مدل استفاده کرد دستیابی به داده های عدم حضور صحیح نیازمند پایش مداوم زیستگاه ؛ثبت نقاط حضور و عدم حضور گونه در سالیان متمادی و دستیابی به اطلاعات کافی در مورد بوم شناسی گونه است.استفاده از مدل های که تنها نیازمند داده های حضور هستند، می تواند از خطاهای ،حاصل از بکارگیری داده های عدم حضور اشتباه جلوگیری کند ،اغلب روش های مدلسازی آماری مبنی بر روشهای رگرسیونی چند متغیره و نیازمند داده های حضور / عدم حضور برای ساخت مدل میباشند. مدلهای خطی عمومی GLM و درخت رگرسیون و طبقه بندی مثالهایی از روشهایی است که برای مدلسازی از داده های حضور / عدم حضور گونه استفاده میکنند. در هر صورت در اغلب موارد دادههای عدم حضورقابل اطمینان وجود ندارد. بنابراین از دیگر روشهایی که تنها مبتنی بر دادههای حضور گونه هستند مانند ENFA GARP و MaxEnt استفاده میشود.
مدلسازی با روش ماکزیمم آنتروپی MaxEnt
MaxEnt یکی از الگوریتم های بسیار رایج یادگیری ماشینی است. اصل MaxEnt به حداکثر آنتروپی یا نزدیک به واقعیت بر میگردد. ماکزیمم آنتروپی یا حداکثر آشفتگی نام قانون دوم ترمودینامیک است ، که آن را به نام قانون افزایش آشفتگی نیز می شناسند. اولین کسی که از این قانون در جایی غیراز مباحث ترمودینامیک صحبت کرد آقای ادوین تامپسون بود او از این قانون در تئوری اطلاعات استفاده کرد.
اصل ماکزیمم آنتروپی
اصل ماکزیمم آنتروپی بیان می دارد که در تخمین یک توزیع نامعلوم توزیعی نزدیک به واقعیت است که دارای حداکثر آشفتگی است . در مدل سازی زیستگاه این به معنی انتخاب توزیعی است که به توزیع یکنواخت نزدیک تر باشد. Shannon آنتروپی را به صورت یک معیار از تعداد گزینه های درگیر در وقوع یک رویداد توصیف کرده است. کاربرد قاعده حداکثر آنتروپی برای توزیع گونه توسط قوانین ترمودینامیک فرآیندهای بوم شناختی حمایت میشود. طبق دومین قانون ترمودینامیک در سیستمهای بسته فرآیند در مسیر حداکثر آنتروپی پیش میرود. بنابراین در غیاب تاثیر عوامل محدود کننده دیگر نسبت به محدودیتهای اعمال شده در مدل، توزیع جغرافیایی گونه تمایل به حداکثر آنتروپی را دارد.
برنامه مدلسازی MaxEnt توسط Phillips و همکارانش نوشته شده است. MaxEnt از روشهای فقط حضور برای مدلسازی توزیع گونه ها محسوب میشود. این مدل برای یک گونه توسط تعدادی لایه محیط زیستی همراه با تعدادی نقاط حضور گونه بدست می آید و مطلوبیت هر سلول در زیستگاه را به صورت تابعی از متغیرهای محیط زیستی بیان میکند. ارزش بالای هر سلول نشان دهنده این است که آن سلول شرایط مطلوبی برای آن گونه دارد. مدل محاسبه شده امکان توزیع جمعیت را در تمامی سلولها بیان میکند. توزیع منتخب، آن قسمتی است که به واقعیت نزدیکتر می باشد و برای هر متغیر باید چنین وضعیتی وجود داشته باشد.
طبق بررسی Ausin مدلسازی آماری توزیع گونه ها شامل 3 قسمت است:
1. مدل بومشناختی در خصوص تئوری بوم شناختی استفاده شده
2. مدل داده در خصوص جمع آوری داده ها
3. مدل آماری درباره تئوری آماری.
مکسنت یک مدل آماری است و برای اینکه بتوان توزیع گونه را بدست آورد باید ارتباطی را میان این مدل با دو جزء دیگر مدلسازی (مدل داده و مدل بومشناختی)ایجاد کرد.گام مهم در فرموله کردن مدل بومشناختی روش MaxEnt ، استفاده از یک مجموعه ویژگیهای مطلوب است. این ویژگیها در واقع فاکتورهای محیط زیستی محدود کننده توزیع جغرافیایی گونه هستند. لایه های محیط زیستی برای تولید مشخصه هایی که توزیع احتمالی گونه را محدود می کنند بکار میروند. انواع مختلف مشخصه ها شامل Linear ، Quadratic ، Hinge ، Product و Threshold میباشد
Linear Feature : توزیع خروجی برای گونه باید دارای همان مقدار امید ریاضی باشد که متغیرهای محیط زیستی نقاط نمونه دارند.
Quadratic Feature : مجذور متغیرهای محیط زیستی است و توزیع خروجی دارای همان مقدار واریانس و امید ریاضی میباشد که متغیرهای محیط زیستی نقاط نمونه دارند.
Product Feature : حاصلضرب دو متغیر محیط زیستی است که به صورت Linear و Quadratic بکار رفته اند و توزیع خروجی دارای کواریانس مشابه با متغیرهای محیط زیستی نمونه میباشد.
Threshold Feature : به صورت باینری 0 و 1 میباشد. وقتی متغیری ارزش بالاتر از آستانه داشته باشد 1 میگیرد و
برعکس اگر ارزش متغیر پایینتر از آستانه باشد صفر میشود.
Hinge Feature : مشابه Linear Feature است اما در زیر آستانه قرار میگیرد.
Auto Feature ) : امکان استفاده از تمام تصاویر را با توجه به تعداد نقاط حضور میدهد.
آماده سازی داده ها برای ورود به مدل MaxEnt
برای کار با نرم افزار MaxEnt با تعدادی ورودی، خروجی و پارامتر روبرو هستیم. ورودی ها همان اطلاعات حضور گونه و لایه های محیط زیستی هستند. فرمت لایه های محیط زیستی Ascii است. برای داده ها اگر از فایل اکسل استفاده شود فرمت داده ها باید csv باشد. اولین خط، عنوان است و سایر خطوط حاوی اطلاعات مربوط به گونه و طول و عرض جغرافیایی میباشد.
اجرای تجزیه و تحلیل
روش ماکزیمم آنتروپی در نرم افزار MaxEnt اجرا میشود. در این بخش داده های حضور گونه و همچنین لایه های زیستگاهی وارد آنالیز میشوند. در این روش از 30 % نقاط حضور به صورت تصادفی برای داده های آموزشی و از 70 % باقیمانده برای ارزیابی نتایج مدل استفاده می شود. این کار به این منظور انجام می گیرد تا از 70 درصد از نقاط حضور با نام Train data برای کالیبره کردن مدل و 30 درصد از آن ها با نام Test data برای بررسی صحت مدل استفاده می شود.
پارامترهای خروجی
در خروجی MaxEnt فایلهای مختلفی وجود دارد. مکسنت دو نوع خروجی ارائه می دهد. خروجی خام مدل مکسنت یک تابع نمایی است، که یک مقدار احتمال را به هر نقطه در منطقه مورد مطالعه نسبت می دهد. مقادیر خام وابسته به تعداد نقاط حضور و نقاط پس زمینه است، زیرا جمع همه مقادیر با هم باید یک باشد.حالت دیگری نیز برای خروجی های خام وجود دارد که حالت تغییر یافته به صورت تجمعی است، در این حالت مقادیر بین صفر تا صد تغییر می کنند . MaxEnt به طور منظم به روز می شود تا قابلیت های جدیدی برای متناسب ساختن کاربردهای گسترشی را شامل شوند. در نسخه های جدید برنامه یک حالت خروجی منطقی نیز ارائه شده است.
خروجی اجرای مدل به صورت سه فایل ارائه می شود:
• یک فایل با پسوند html که اصلی ترین فایل خروجی می باشد که شامل محاسبه های آماری، نقشه ها، تصویرمدل و پیوند فایل های دیگر می باشد، هم چنین شامل پارامترها وتنظیماتی است که برای اجرا کردن مدل استفاده شده اند.
• یک فایل با پسوند asc شامل نقشه پیش بینی ها با قالب ( format ascii )یک فایل با پسوند png که شامل تصویر پیش بینی توزیع می باشد.
• نقشه های مختلف ونمودارها در دایرکتوری plot ذخیره می شوند.
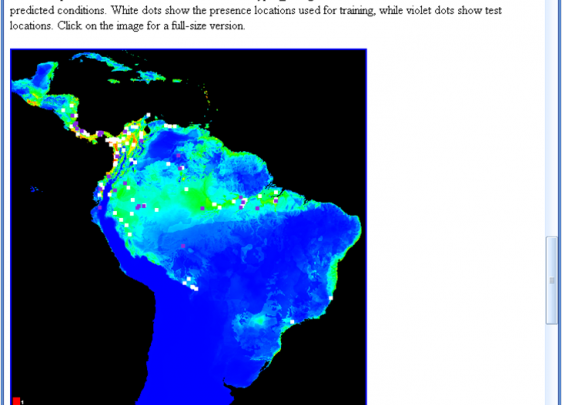
نقشه پیشبینی ساخته شده توسط MaxEnt یک نقشه احتمالی پیوسته است. همچنین MaxEnt توسط آزمون جک نایف متغیرهای موثر را نیز تعیین میکند.
مزایا و معایب داده های حضور/عدم حضور
برخی از مباحث چاپ شده حاکی از آن هستند که داده های تنها حضوری از چند لحاظ ما را از مسائل سوابق عدم حضور غیرمعتبر رها می سازند با تأکید ویژه بر اینکه عدم حضورها باعث پیدایش تأثیرات قوی تعاملات زیستی، محدودیت های پراکندگی و اختلالاتی می شوند که ممکن است مانع مدل سازی توزیع های ناشناخته شوند. به هرحال، رکوردهای حضور تنها تحت تأثیر تعدادی عوامل تأثیرگذار بر عدم حضورها قرار می گیرند. اگر گونه ای در یک منطقه زیست محیطی مناسب وجود نداشته باشد چون مثلاً اختلالات گذشته موجب انقراض آنها در محل شده است سیگنال آن عدم حضور در توزیع و پخش سوابق حضور مشاهده خواهد شد: هیچ گونه سابقه حضور در منطقه آشفته وجود نخواهد داشت. صرفنظر از اینکه آیا عدم حضورها در مدل سازی مورد استفاده قرار می گیرند، الگو در سوابق حضور حاکی از نامناسب بودن این منطقه خواهد بود واین مدل تحت تأثیر این الگوسازی قرار می گیرد. همینطور اگر آشکارپذیری یک گونه خاص در هر مکانی فرق داشته باشد آنگاه نه تنها این امر منجر به برخی عدم حضورهای غلط در داده های حضور/عدم حضور می شود الگوی حضورها در داده های تنها حضوری را نیز تحت تأثیر قرار می دهد. بنابراین به طور طبیعی می توان نتیجه گرفت که اگر بدون داده های عدم حضور کار کنیم محدودیت هایی که اغلب به داده های عدم حضور نسبت داده شده اند مطرح نمی شوند از جمله این واقعیت که گونه ها کاملاً آشکار نمی شوند و کل زیستگاه مناسب را اشغال نمی کنند. این طرز تفکر بدین معناست که ما به توصیف مسئله مدل سازی تنها حضوری به عنوان کسی که سعی می کند همین کمیت مدل سازی شده با داده های حضور/عدم حضور را مدل سازی کند یعنی احتمال حضور یک گونه که به طور دقیق تر در ذیل تعریف شده است نزدیک خواهیم شد. از اینجا به بعد فرض می کنیم که داده های موجود برای مدل سازی تنها حضوری هستند یعنی مجموعه ای از مکان ها درمحدوده L، چشم انداز مورد نظر که در اینجا گونه مشاهده شده است.
و در پایان….
این مدل آنتروپی نسبی بین دو دانسیته احتمال که در فضای ویژگی تعریف شده اند را به حداقل می رساند. داده های تنها حضوری یک منبع باارزش هستند و به طور بالقوه برای مدل سازی همین روابط اکولوژیکی داده های حضور/عدم حضوراستفاده شده اند مشروط بر آنکه خطاها به استثنای عدم تشخیص پذیری میزان شیوع برطرف شوند. به هرحال اگر داده های ممیزی حضور/عدم حضور قابل دسترس باشند به طور کلی توصیه می شود که از یک روش مدلسازی حضور/عدم حضور استفاده کنیم چون در آن صورت است که مدل ها به نسبت کمتر در معرض مسائل خطاهای انتخاب نمونه قرار می گیرند. بویژه، داده های حضور/عدم حضور اطلاعات بسیار بهتری درباره میزان شیوع به ما نشان می دهند چون حتی اگرچه برخی مشکلات به دلیل آشکارسازی ناقص وجود دارند اما آنها مسئله اصلی عدم تشخیص پذیری راحل و فصل می کنند. داده های تنها حضوری از چند لحاظ ما را از مسائل سوابق عدم حضور غیرمعتبر رها می سازند با تأکید ویژه بر اینکه عدم حضورها باعث پیدایش تأثیرات قوی تعاملات زیستی، محدودیت های پراکندگی و اختلالاتی می شوند که ممکن است مانع مدل سازی توزیع های ناشناخته شوند. و با توجه به وضعیت ایران از نظر بودجه و هم چنین نبود متخصص کافی برای شناسایی نمایه های حضورگونه و از این طریق پی بردن به داده های عدم حضور و ارزیابی زیستگاه با صرف کمترین زمان ممکن و همچنین با کمترین هزینه می تواند روش مناسبی برای ارزیابی زیستگاه در ایران باشد.