مقدمه:
ریز مقیاس نمایی یعنی فرآیند حرکت از پیش بینی کننده های بزرگ مقیاس به پیش بینی شونده ها در مقیاس محلی. روش های ریز مقیاس سازی به دو دسته آماری و دینامیکی تقسیم می شوند:
روش دینامیکی : مدل هایی که برای ریز مقیاس نمایی دینامیکی استفاده می شوند بسیار شبیه همان مدل های گردش عمومی هستند، منتها گام های زمانی و مکانی شبکه ریزتر و دقیق تر هستند پس این مدل ها همان پیچیدگی های مدل های اقلیمی را دارا می باشند .
انواع مدل های دینامیکی می توان به REGCM , NCEP/RSM و یا WRF اشاره کرد.
روش آماری : هدف در این روش توسعه روابط بین متغیر های اقلیمی بزرگ مقیاس و متغیر های منطقه ای و در نهایت شناسایی روابط بین سیستم ها از روی داده های مشاهداتی می باشد.درحقیقت این مدل ها روابطی را بین پیش بینی کننده ها که همان متغیر های بزرگ مقیاس هستند و پیش بینی شونده ها که همان متغیر های منطقه ای می باشند گسترش می دهند سپس متغیر های اقلیمی محلی را برای آینده پیش بینی می کنند .
روش های آماری به چند قسمت کلی تقسیم بندی می شوند:
- روش های مبتنی بر آلودگی آب و هوا
- روش های تصادفی ( مولد های هوا شناسی)
- روش های رگرسیونی
مدل هایی که برای این روش استفاده می شوند عبارتند از:
WGEN, CLIMGEN, LARS-WG, SDSM, ASD, Magicc-Scengen
این مدل ارتباطات آماری بین پیش بینی کننده های بزرگ مقیاس و پیش بینی شونده ها در مقیاس محلی را بر اساس روش رگرسیون خطی چندگانه برقرار می کند.
این ارتباطات با استفاده از داده های مشاهداتی ایستگاه و خروجی های مدل های گردش عمومی در دوره مشابه دیدبانی ایجاد می شوند. فرض بر این است که این روابط در آینده نیز صادق باشند، به عبارت دیگر فرض اساسی در ریز مقیاس نمایی آماری مستقل از زمان بودن این ارتباطات است قبل از انجام فرآیند ریزمقیاس نمایی توسط این مدل داده های مشاهداتی و داده های مدل های گردش عمومی با توجه به مقادیر میانگین و انحراف معیار آنها در دوره مورد نظر نرمالیزه می شوند؛ اینکار به این دلیل انجام می شود که مدل های گردش عمومی نمی توانند به خوبی اقلیم محلی را مانند دیدبانی شبیه سازی نمایند؛ لذا مقایسه این دو باهم قبل از نرمالیزه کردن می تواند موجب همبستگی های غیرمعقول گردد.
متغیرهای پیش بینی کننده اطلاعات مربوط به حالت بزرگ مقیاس جو را فراهم می کنند؛ در حالیکه متغیرهای پیش بینی شونده حالت جو را در مقیاس نقطه ای/ محلی مشخص می کنند.
کنترل کیفی: در این مرحله دادههای دیدهبانی (پیشبینیشونده) از نظر تعداد دادهها، بیشینه، کمینه، دادههای مشکوک و مفقود کنترل میشود.
غربالگری متغیرها: ارتباط بین دادههای دیدهبانی (پیشبینیشونده) با دادههای بزرگ مقیاس (پیشبینیکننده) دارای شدت و ضعف گوناگون است. هدف از این مرحله، یافتن قویترین ارتباط پیشبینیکنندهها با پیشبینیشوندهها است. در این بخش سه موضوع مورد بررسی قرار میگیرد: همبستگی فصلی، همبستگی جزئی و نمودار پراکنش. اگر متغیر مانند بارش شرطی باشد که باید ابتدا تر یا خشک بودن روز پیشبینی شود و سپس مقدار بارش، در آن صورت گزینه شرطی را انتخاب میکنیم. به عبارت دیگر ارتباط بین بارش و پیشبینیکنندهها غیرمستقیم است و توزیع آنها دارای چولگی است؛ اما در مورد دما ارتباط بین آن با پیشبینیکنندهها مستقیم در نظر گرفته شده و توزیع آن نرمال است، بنابراین برای دمای بیشینه غیر شرطی انتخاب میشود. سطح همبستگی معمولا 05/0 در نظر گرفته میشود. غربالگری با در نظر گرفتن میزان همبستگی بین پیشبینیشونده- پیشبینیکننده، همبستگی جزئی و نمودار پراکندگی انجام می شود.
واسنجی: در این مرحله مدلهای آماری سالانه، فصلی و ماهانه مبتنی بر معادلات وایازی چندگانه با به کارگیری دادههای پیشبینیشونده و پیشبینیکننده روزانه ساخته می شوند. مشخصات و پارامترهای مدلهای آماری یاد شده (مانند متادیتا، دوره واسنجی، نوع مدل، پیشبینیکنندههای به کار رفته در ساخت مدل و غیره) در فایل استانداردی با پسوند PAR. نگهداری می شوند.
تولید داده: عملگر تولید داده مجموعهای از دادههای روزانه پیشبینیشونده را با لحاظ سری دادههای روزانه پیشبینیکنندهها و بر اساس معادلات وایازی پایهگذاری شده در بخش واسنجی تولید میکند. این گام در مدل SDSM مسئولیت راستیآزمایی معادلات ریزمقیاسنمایی طراحی شده در گام واسنجی را به عهده دارد. در این مرحله میتوان حداکثر تا 100 سری داده روزانه را تولید کرد که هیچکدام از سریهای تولیدی ارجحیتی بر یکدیگر ندارند.
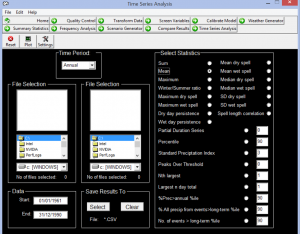
تجزیه و تحلیل دادههای دیدهبانی و ریزمقیاسشده: تجزیه و تحلیل داده شامل بررسی میانگین، بیشینه، کمینه، واریانس، مقادیر آستانه، صدکها، روزهای تر و خشک و غیره در مقیاسهای گوناگون سالانه، فصلی و ماهانه انجام میشود.
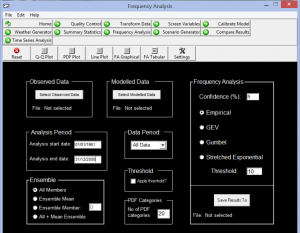
تجزیه و تحلیل فراوانی: در این مرحله امکان ترسیم توزیعهای گوناگون برای دادهها فراهم میشود. برای دیدن نمودارها از گزینههای Observed data و Modeled data فایل دادههای دیدهبانی و مدلشده مشخص میشود. پس از آن منحنیهای Q-Q، Pdf، منحنی تجزیه و تحلیل فراوانی و غیره قابل ترسیم میشوند. یکی از توانمندیهای این بخش برازش توزیعهای آماری از جمله توزیع تجربی، گامبل و غیره بر سری دادهها است.
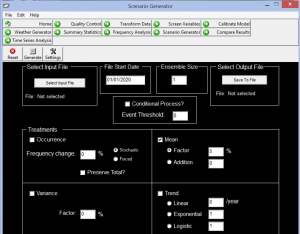
تولید سناریو: در این مرحله با استفاده از معادلات ریزمقیاسنمایی ایجاد شده در قسمت واسنجی و دادههای مدل گردش عمومی، دادههای روزانه متغیرهای پیشبینیشونده برای دهههای آینده تولید میشود. پیشبینیکنندههای مدلهای گردش عمومی باید نسبت به یک دوره مرجع (اجرای کنترل) نرمالیزه شده و برای تمامی متغیرهای مورد استفاده در قسمت واسنجی در دسترس باشند.
برخی از متغییرهای پیش بینی کننده بزرگ مقیاس مدل های گردش عمومی مورد استفاده در مدلSDSM عبارتند از:
دمای 2 متری، فشار سطح متوسط دریا، ارتفاع ژئوپتانسیلی 500 میلیباری، ارتفاع ژئوپتانسیلی سطح 850 میلیباری، رطوبت نسبی مجاورسطح زمین، رطوبت نسبی سطح 500 میلیباری، رطوبت نسبی سطح 850 میلیباری، رطوبت ویژه مجاور سطح زمین، رطوبت ویژه سطح 500 میلیباری، رطوبت ویژه سطح 850 میلیباری، سرعت باد زمینگرد، تاوایی، مولف مداری باد، مولفه نصف النهاری باد، واگرایی و سمت باد. از بین متغیرهای فوق فقط متغیر سمت باد نرمالیزه نمی شود.
نحوه اجرا مدل SDSM:

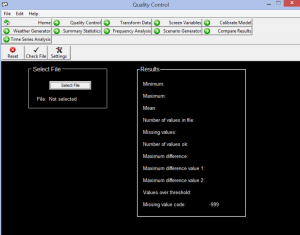
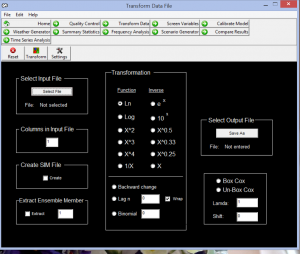
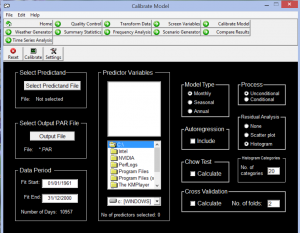
شکل شماره 7. کالیبره کردن مدل
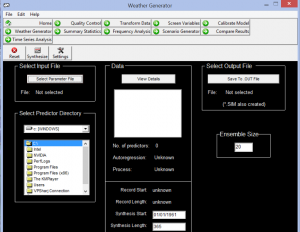
شکل شماره 8.تولید داده های مصنوعی آب وهوایی
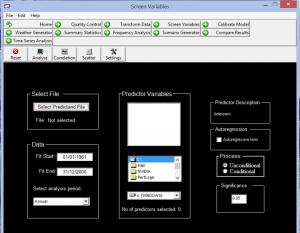
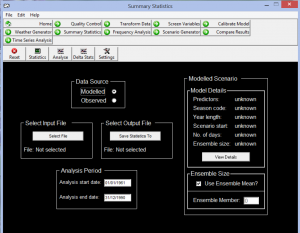
شکل شماره 9 . آنالیز داده های مشاهداتی و ریز مقیاس شده
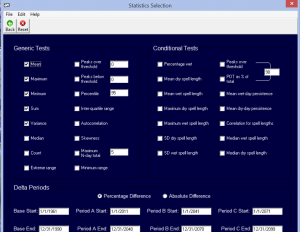
شکل شماره 10. آنالیز داده های تولید شده در مرحله summery statistics
منابع:
الطافی ن، 1396، پروژه کارشناسی، معرفی مدل های بررسی کننده تغییر اقلیم، دانشکده محیط زیست کرج.
www.sdsm.org. uk
مشاهده ادامه این مطلب فقط برای اعضای سایت فراگیر علمی تخصصی محیط زیست فراهم می باشد. خواهشمنداست جهت مشاهده کامل این نوشته، ثبت نام کنید و به حساب کابری خود وارد شوید. ثبت نام در اینجا کاملاً رایگان است.
مشاهده ادامه این مطلب فقط برای اعضای سایت فراگیر علمی تخصصی محیط زیست فراهم می باشد. خواهشمنداست جهت مشاهده کامل این نوشته، ثبت نام کنید و به حساب کابری خود وارد شوید. ثبت نام در اینجا کاملاً رایگان است.